
Лексикографическая база данных языка повседневного общения "Язык мегаполиса"
1.1. Структура базы данных
База данных выполнена на базе СУБД MS Access 2007 и состоит из 7 основных таблиц.
Таблица 1 (Informants): фактические данные обо всех базовых информантах (то есть людей, осуществивших звукозапись своей речевой коммуникации). В связи с тем, что ответы на многие вопросы не являлись для информантов обязательными, поля этой таблицы заполнены не полностью. Таблица 1а (Speakers): подвыборка говорящих для озвученного словаря.
Таблица 2 (Communicants): фактические данные обо всех коммуникантах (то есть тех людях, с которыми информант общался в течение дня). Эти данные также были получены из анкет, заполненных информантами.
Таблица 3 (Epizodes): описание основных эпизодов речевого дня, полученных в результате прослушивания звукозаписей экспертами, информация об участниках разговора, о времени начала и конца каждого сюжета, о его теме, месте и времени, когда разговор состоялся, о типе коммуникативного сценария, социальных ролях говорящих и других условий коммуникации.
Таблица 4 (Frases): реплики повседневной речи в орфографической расшифровке с указанием говорящего и коммуникативного эпизода.
Таблица 5 (WordsGrammar): центральная таблица словарной базы, содержащая подробное лексикографическое описание словоформ: часть речи, лемма, постоянные грамматические характеристики, словоизменительные характеристики, тематическое поле, стилистические пометы, валентность и др., а также фразовый контекст и ссылку на говорящего и коммуникативный эпизод.
Таблица 6 (PhonRealization): наиболее типичные редуцированные формы с указанием лексемы, фонетической транскрипции, фразовым контекстом и ссылкой на говорящего и коммуникативный эпизод.
Таблица 7 (PhonWords): массив отсегметнированных словоформ повседневной речи для научных исследований и построения мультимедийных словарей с фразовым контекстом и ссылкой на говорящего и коммуникативный эпизод.
1.2. Формы базы данных
Навигация в речевом корпусе поддерживается посредством пользовательского интерфейса специализированной базы данных. Для удобства работы пользователя разработаны наглядные формы. Приведем некоторые из них
При вызове информационной базы открывается титульное окно:

Нажатием кнопки «Открыть», появляется возможность вызова «Главного меню». Здесь представлены основные объекты анализа данных.

Нажатием на кнопку «Словоформы с аннотацией» активизируется основная лексикографическая форма. Здесь представлены все лексикографические данные, фразовый контекст, код говорящего (с псевдонимом для транскриптов расшифровок), ссылка на код эпизода. Нажатием на кнопку с изображением колокольчика осуществляется звуковое воспроизведение фразового контекста.

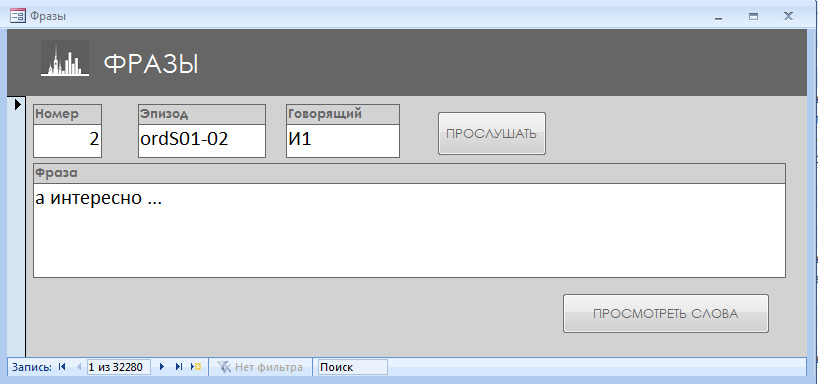
Форма «Фразы» открывается путем вызова клавиши «Реплики повседневной речи». Все реплики озвучены (используется кнопка «ПРОСЛУШАТЬ»), их орфографическая расшифровка снабжена синтагматической разметкой.
База данных является масштабируемой, то есть предполагает увеличение объектов и параметров описания.